PD分离
LLM在线推理服务通常需要满足TTFT和TPOT两项性能指标,而传统的Contiguous Batching调度策略将Prefill和Decode请求混合在一起调度,导致P和D会互相抢占计算资源,影响性能指标无法最大程度的利用计算资源。为解决上述矛盾,将Prefill和Decode两阶段拆分到独立的计算资源并行执行,从而同时降低TTFT和TPOT并提升吞吐量。
xLLM PD分离功能主要通过以下三个模块实现:
- etcd: 存储实例信息等元数据
- xLLM Service: 调度请求和管理所有计算实例
- xLLM: 请求计算实例
整体架构图如下:
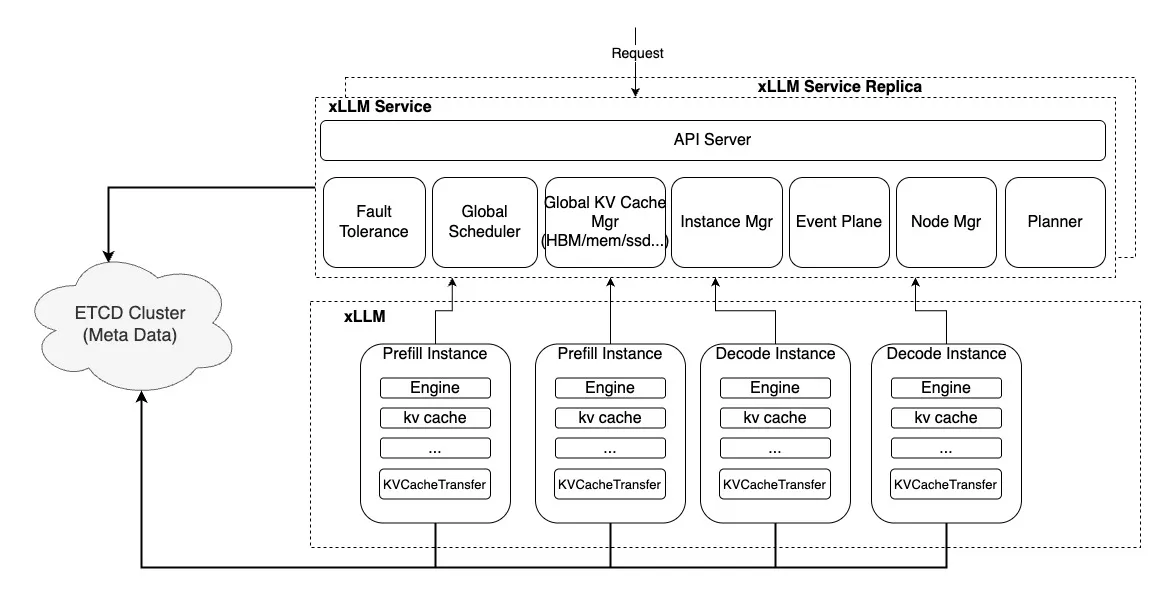
功能使用示例
Section titled “功能使用示例”安装相关依赖
Section titled “安装相关依赖”- xLLM: 参见安装编译
- xLLM Service: 参见xLLM Service
启动PD分离服务
Section titled “启动PD分离服务”- 启动etcd
./etcd- 启动xLLM Service
ENABLE_DECODE_RESPONSE_TO_SERVICE=true ./xllm_master_serving --etcd_addr="127.0.0.1:12389" --http_server_port 28888 --rpc_server_port 28889 --tokenizer_path=/path/to/tokenizer_config_dir/-
启动xLLM
-
以Qwen2-7B为例
- 启动Prefill实例
Terminal window /path/to/xllm --model=Qwen2-7B-Instruct \--port=8010 \--devices="npu:0" \--master_node_addr="127.0.0.1:18888" \--enable_prefix_cache=false \--enable_chunked_prefill=false \--enable_disagg_pd=true \--instance_role=PREFILL \--etcd_addr=127.0.0.1:12389 \--transfer_listen_port=26000 \--disagg_pd_port=7777 \--node_rank=0 \--nnodes=1 - 启动Decode实例
Terminal window /path/to/xllm --model=Qwen2-7B-Instruct \--port=8020 \--devices="npu:1" \--master_node_addr="127.0.0.1:18898" \--enable_prefix_cache=false \--enable_chunked_prefill=false \--enable_disagg_pd=true \--instance_role=DECODE \--etcd_addr=127.0.0.1:12389 \--transfer_listen_port=26100 \--disagg_pd_port=7787 \--node_rank=0 \--nnodes=1
需要注意:
-
PD分离需要读取
/etc/hccn.conf文件,确保将物理机上的该文件映射到了容器中 -
etcd_addr需与xllm_service的etcd_addr相同
- 启动Prefill实例