多流并行
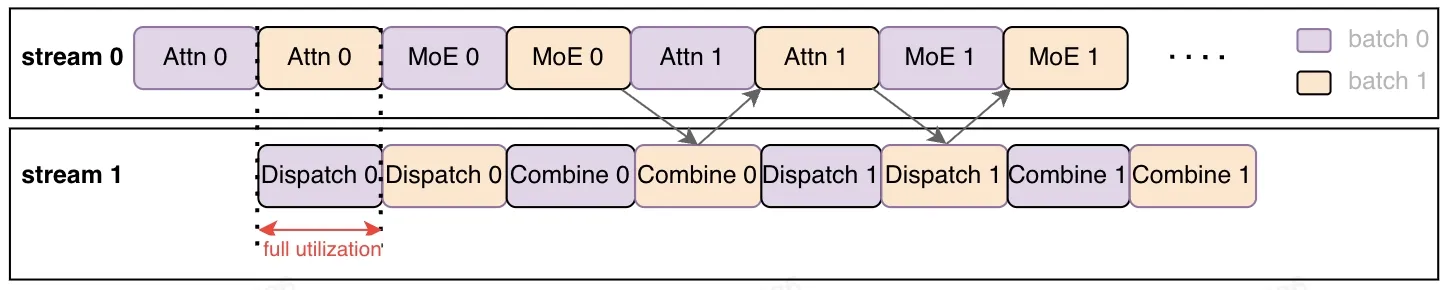
大模型分布式推理场景中需要引入额外的通信操作,将不同设备上的计算结果聚合在一起。以Deepseek这类大规模的MoE模型为例,分布式规模通常较大,通信开销也会随之变大。计算和通信都采用同一个stream的话,在通信的同时,device计算资源会出现浪费,一直等待通信完成才能开始后面的计算。
xLLM在模型图层支持了多流并行功能,将输入的batch拆分成2个micro batches,一个流执行一个micro batch的计算操作,另一个流执行另一个micro batch的通信操作,计算和通信同时执行,从而掩盖通信开销。
xLLM中提供了gflags参数enable_multi_stream_parallel,默认false,如需开启在xLLM的服务启动脚本中设置为true即可,示例如下:
--enable_multi_stream_parallel=trueprefill双流并行开启后,基本可掩盖75以上的通信开销,在DeepSeek-R1模型上,只输出1个token的情况下
- TTFT下降 7%
- 吞吐 提升7%