MoE负载均衡(EPLB)
MoE模型依赖动态路由分配tokens给专家,但实际部署中因数据分布不均,导致专家负载失衡(部分过载、部分闲置)。专家冗余调整(如新增/删除副本)需要消耗额外显存,并可能因权重迁移影响推理延迟,如何高效、平滑地完成是一大挑战。为此,采用专家冗余策略(复制热点专家)结合分层和全局动态负载均衡实现了动态的MOE负载均衡。
xLLM MoE负载均衡(EPLB)功能主要通过以下三个模块实现:
- eplb manager: 负责专家负载并收集并管理专家分布更新更新,采用逐层更新机制,根据专家负载变化情况判断是否更新该层。
- eplb excutor: 实际专家分布更新执行器。
- eplb policy: 新专家负载表生成策略。
整体架构图如下:
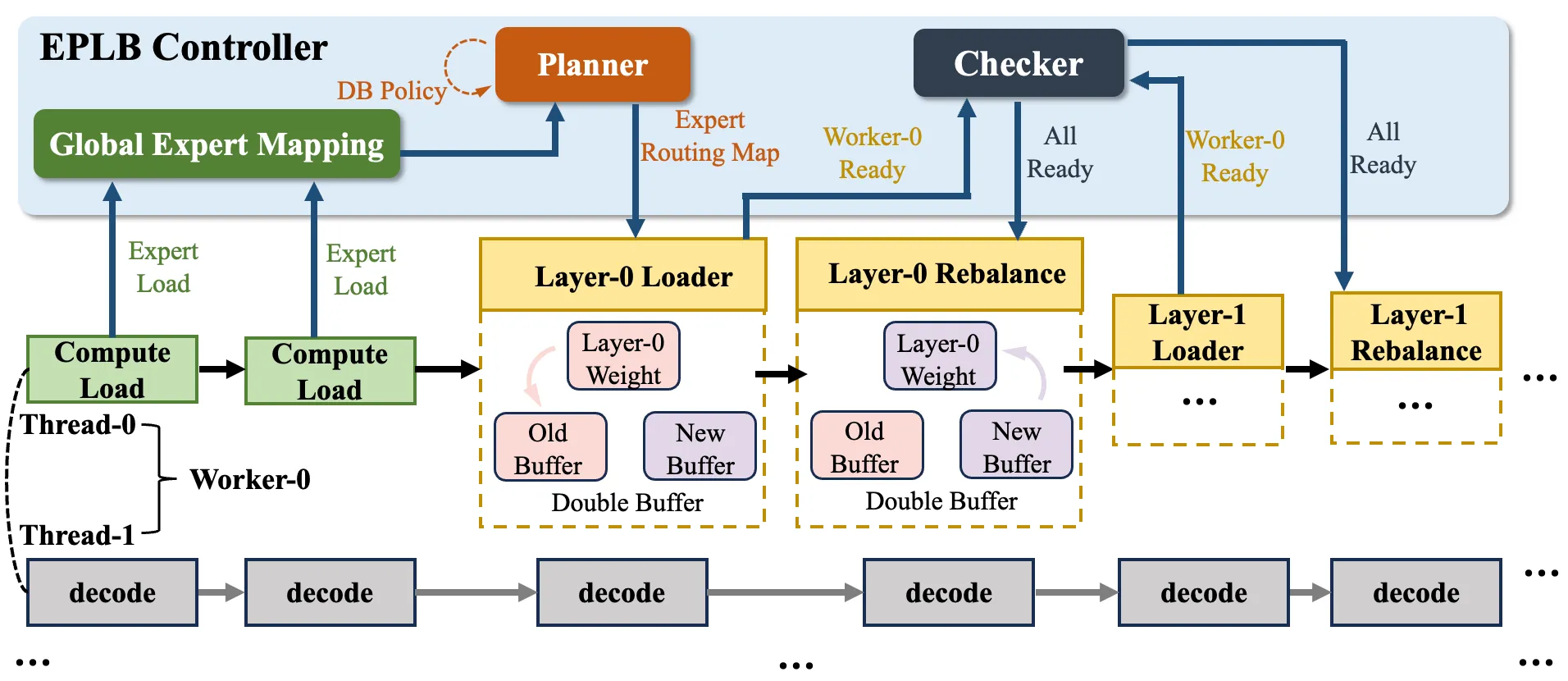
只需在启动 xLLM 时加上下面的 gflag 参数即可: 替换为实际的Device个数 ep_size要与device个数保持一致
- xLLM中提供了gflags参数
enable_eplb,默认false,如需开启动态专家负载均衡,在xLLM的服务启动脚本中设置为true即可。 expert_parallel_degree与ep_size为moe相关参数,expert_parallel_degree需要设置为2,ep_size要与实际NPU/GPU卡个数保持一致。参考 moe_paramseplb_update_interval为专家分布更新时间间隔,单位为妙,默认值为1000.- 专家分布更新采用根据专家负载的逐层更新机制,当某一层专家的前后两次的负载相似度小于
eplb_update_interval时选择更新该层,默认值为1,取之范围为(0,1)。
--enable_eplb=true --expert_parallel_degree=2 --ep_size=16 --eplb_update_interval=2000 --eplb_update_threshold=0.9-
采用更加细粒度的专家更新机制。
-
与调度层结合,通过请求batch的重组实现更好的负载均衡。