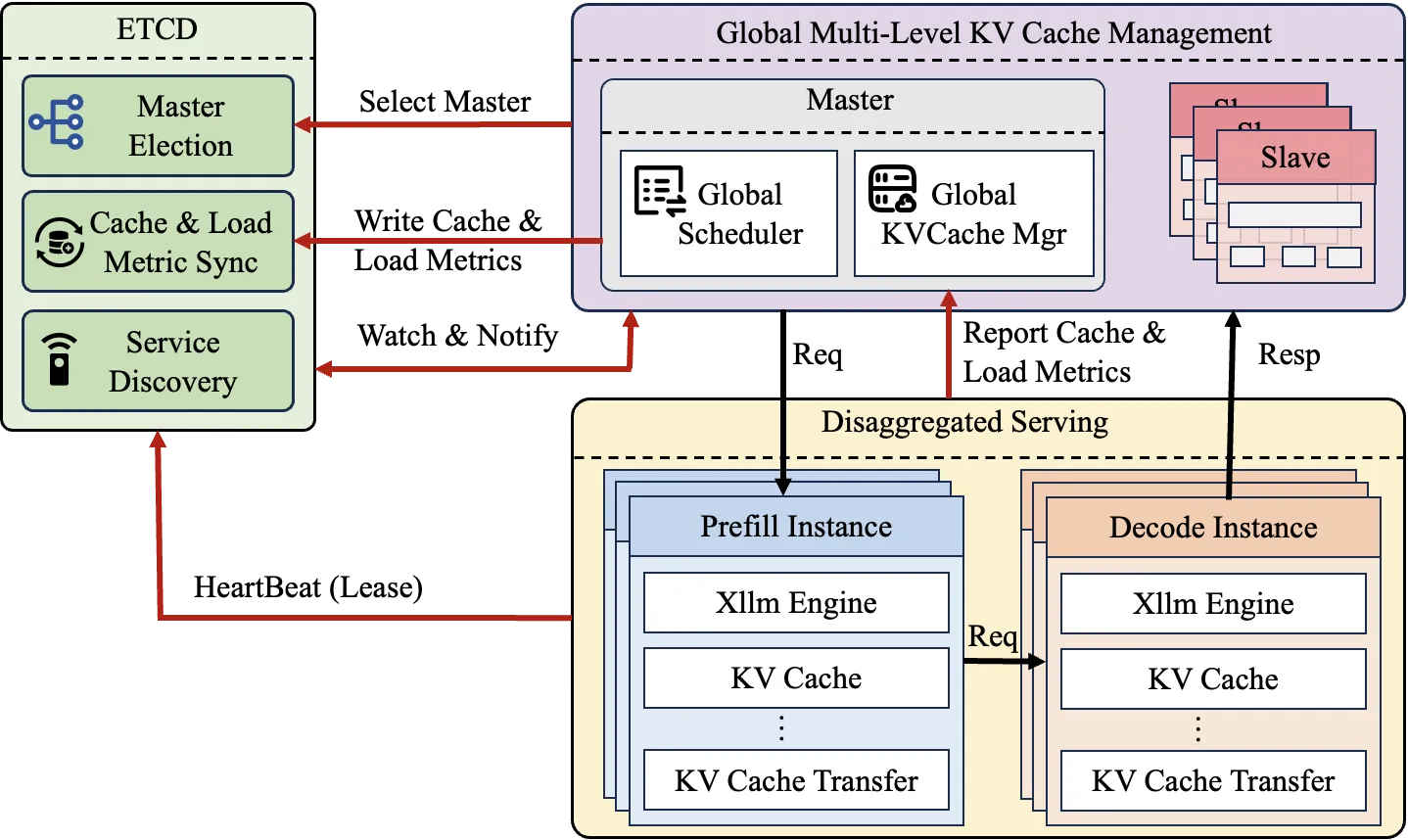
全局多级KV Cache
大型语言模型(LLM)解码阶段因自回归生成需频繁访问历史KV缓存,导致显存带宽成为瓶颈。随着模型规模与上下文窗口扩大(如128K Token消耗超40GB显存),单卡显存压力剧增。现有方案(如vLLM)在长上下文场景下存在明显局限:预填充耗时激增、解码阶段显存带宽争抢严重,为满足SLO(TTFT<2s, TBT<100ms)常需过量预留资源,致使GPU利用率不足40%,且难以利用跨服务器资源。为此,我们提出分布式全局多级KV缓存管理系统,采用存算一体架构以突破单机资源限制。
xLLM 全局KV Cache功能主要通过以下三个模块实现:
- etcd: 集群服务注册、负载信息同步及全局缓存状态管理
- xLLM Service: 调度请求和管理所有计算实例
- xLLM: 请求计算实例
整体架构图如下:
功能使用示例
Section titled “功能使用示例”安装相关依赖
Section titled “安装相关依赖”- xLLM: 参见快速开始
- xLLM Service: 参见xLLM Service
- etcd启动配置:
./etcd --listen-peer-urls=http://0.0.0.0:10999 --listen-client-urls=http://0.0.0.0:10998- xLLM Service启动配置:
./xllm_master_serving --etcd_addr="127.0.0.1:10998" --http_server_port 28888 --rpc_server_port 28889 --tokenizer_path=/path/to/tokenizer_config_dir/- xLLM启动添加上下面的 gflag 参数即可:
--enable_service_routing=true--enable_cache_upload=true# PD分离暂时不支持全局KVCache管理--enable_disagg_pd=false