Disaggregated PD
Background
Section titled “Background”LLM online inference services typically need to meet two performance metrics: TTFT and TPOT. Traditional Contiguous Batching scheduling strategies mix Prefill and Decode requests during scheduling, causing Prefill and Decode phases to compete for computational resources. This prevents maximized utilization of computing resources and impacts performance metrics. To resolve this conflict, the Prefill and Decode phases are split to run on independent computational resources, enabling parallel execution. This simultaneously reduces TTFT and TPOT while improving throughput.
Introduction
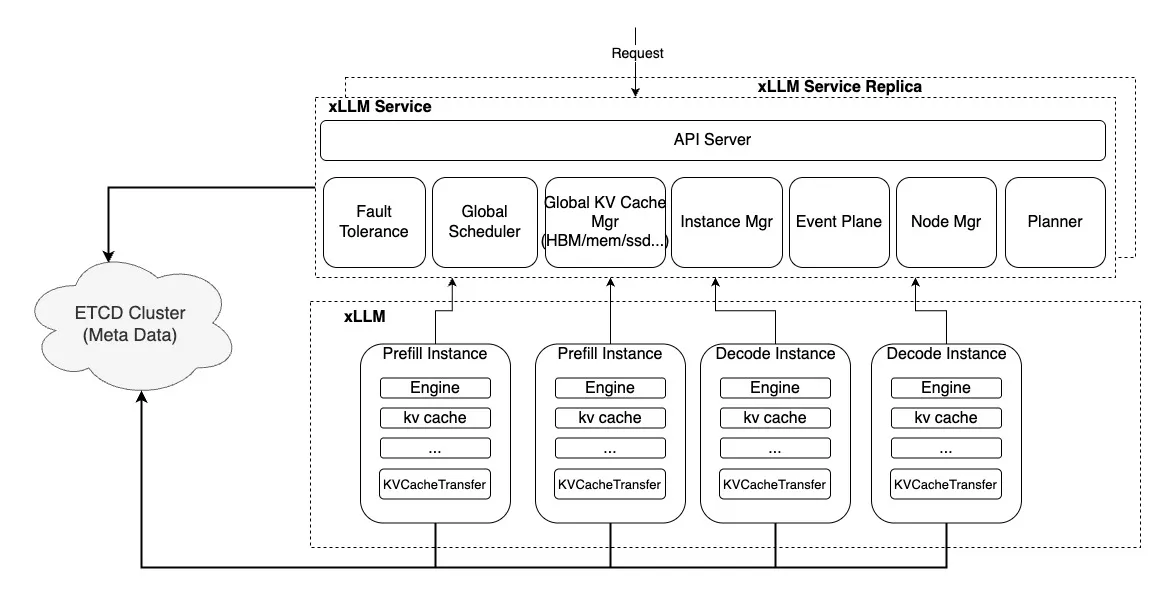
Section titled “Introduction”The xLLM PD Separation feature is primarily implemented through the following three modules:
- etcd: Stores metadata such as instance information.
- xLLM Service: Schedules requests and manages all computing instances.
- xLLM: Handles request computation instances.
The overall architecture is shown below:
Preparation
Section titled “Preparation”Install Dependencies
Section titled “Install Dependencies”- xLLM: Refer to Installation && Compilation
- xLLM Service: Refer to xLLM Service
Obtain Environment Information
Section titled “Obtain Environment Information”Deploying Disaggregated PD Service requires obtaining the Device IP of the machine to create communication resources. Execute the command cat /etc/hccn.conf | grep address on the current AI Server to get the Device IP, for example:
address_0=xx.xx.xx.xxaddress_1=xx.xx.xx.xxaddress_xx represents the Device IP.
Start Disaggregated PD Service
Section titled “Start Disaggregated PD Service”- Start etcd
./etcd- Start xLLM Service
ENABLE_DECODE_RESPONSE_TO_SERVICE=true ./xllm_master_serving --etcd_addr="127.0.0.1:12389" --http_server_port 28888 --rpc_server_port 28889 --tokenizer_path=/path/to/tokenizer_config_dir/- Start xLLM
-
Taking Qwen2-7B as an example
- Start Prefill Instance
Terminal window /path/to/xllm --model=Qwen2-7B-Instruct \--port=8010 \--devices="npu:0" \--master_node_addr="127.0.0.1:18888" \--enable_prefix_cache=false \--enable_chunked_prefill=false \--enable_disagg_pd=true \--instance_role=PREFILL \--etcd_addr="127.0.0.1:12389" \--transfer_listen_port=26000 \--disagg_pd_port=7777 \--node_rank=0 \--nnodes=1 - Start Decode Instance
Terminal window /path/to/xllm --model=Qwen2-7B-Instruct \--port=8020 \--devices="npu:1" \--master_node_addr="127.0.0.1:18898" \--enable_prefix_cache=false \--enable_chunked_prefill=false \--enable_disagg_pd=true \--instance_role=DECODE \--etcd_addr="127.0.0.1:12389" \--transfer_listen_port=26100 \--disagg_pd_port=7787 \--node_rank=0 \--nnodes=1
Important notes:
-
PD disaggregation requires reading the
/etc/hccn.conffile. Make sure this file on the physical machine is mapped into the container. -
etcd_addrmust match theetcd_addrofxllm_service
- Start Prefill Instance
Notice
Section titled “Notice”With the chunked-prefill PD scheduler, the Prefill instance supports prefix cache. When enabled, the scheduler matches existing prefix-cache blocks before calculating the current chunk budget, so cached prompt blocks are not recomputed:
--enable_chunked_prefill=true--enable_prefix_cache=true