Global Multi-Level KV Cache
Background
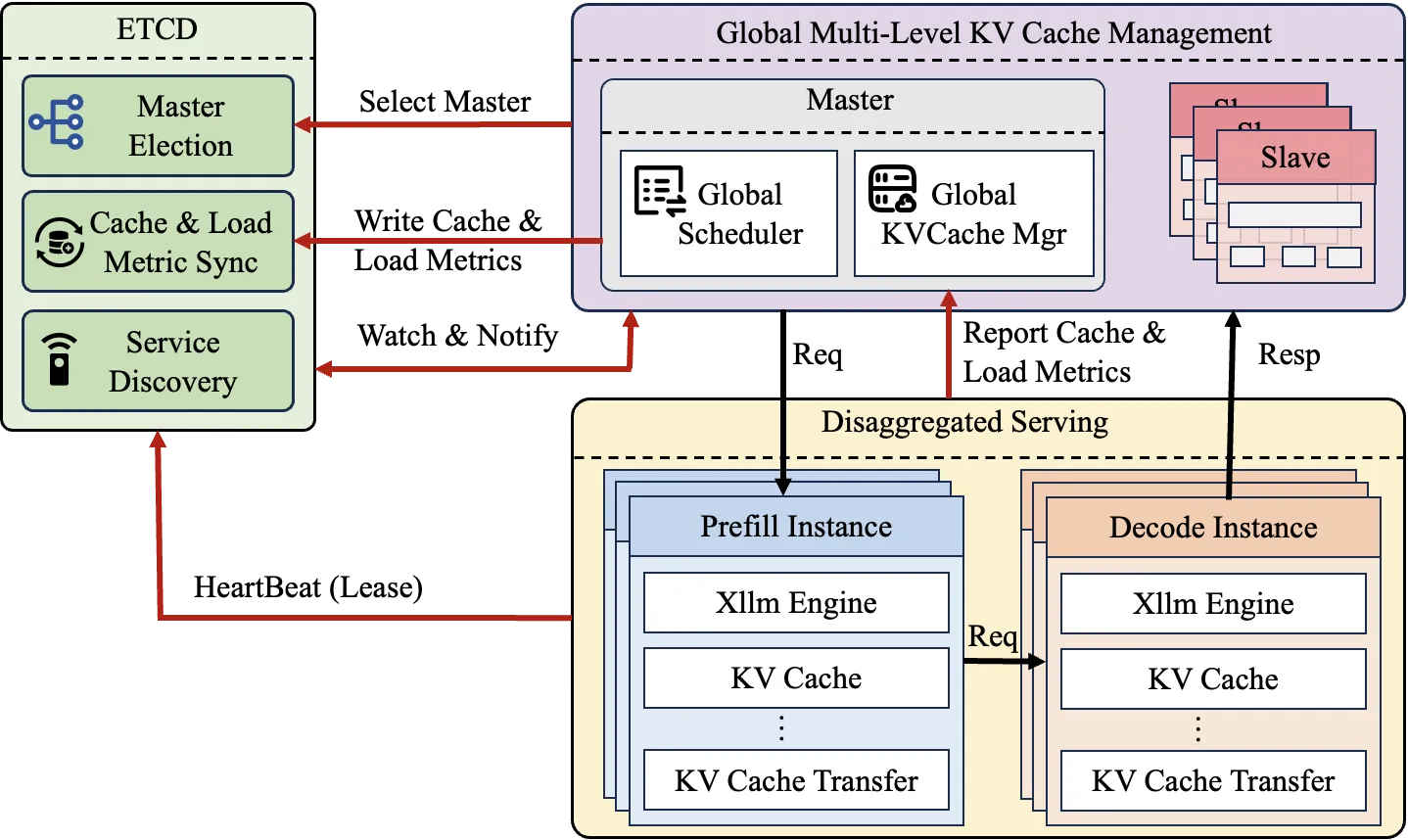
Section titled “Background”In the decoding phase of large language models (LLMs), frequent access to historical KV cache due to autoregressive generation creates a bottleneck in memory bandwidth. As model sizes and context windows expand (e.g., 128K Tokens consuming over 40GB of memory), the pressure on single-device memory increases dramatically. Existing solutions (such as vLLM) exhibit significant limitations in long-context scenarios: prefill time surges, severe memory bandwidth contention during decoding, and the need for excessive resource reservation to meet SLO requirements (TTFT < 2s, TBT < 100ms). This often results in GPU utilization below 40% and difficulties in leveraging cross-server resources. To address this, we propose a distributed global multi-level KV cache management system, adopting a memory-compute integrated architecture to break through single-machine resource constraints.
Feature Introduction
Section titled “Feature Introduction”The xLLM Global KV Cache feature is primarily implemented through the following three modules:
- etcd: For cluster service registration, load information synchronization, and global cache state management.
- xLLM Service: For scheduling requests and managing all compute instances.
- xLLM: The compute instances handling requests.
The overall architecture is shown in the diagram below:
Usage Example
Section titled “Usage Example”Preparation
Section titled “Preparation”Install Dependencies
Section titled “Install Dependencies”- xLLM: Refer to Quick Start
- xLLM Service: Refer to xLLM Service
Usage Instructions
Section titled “Usage Instructions”-
etcd Startup Configuration:
Terminal window ./etcd --listen-peer-urls=http://0.0.0.0:10999 --listen-client-urls=http://0.0.0.0:10998 -
xLLM Service Startup Configuration:
Terminal window ./xllm_master_serving --etcd_addr="127.0.0.1:10998" --http_server_port 28888 --rpc_server_port 28889 --tokenizer_path=/path/to/tokenizer_config_dir/ -
xLLM Startup Configuration: Add the following gflag parameters when starting xLLM:
Terminal window --enable_service_routing=true--enable_cache_upload=true# PD separation currently does not support Global KVCache Management--enable_disagg_pd=false