Multi-stream parallel
Background
Section titled “Background”In distributed inference scenarios for large-scale models, additional communication operations are required to aggregate computation results from different devices. Taking large-scale MoE models like Deepseek as an example, the distributed scale is typically substantial, leading to increased communication overhead.
If both computation and communication are performed on the same stream, the device’s computing resources will remain idle while waiting for communication to complete, resulting in wasted computational capacity before subsequent calculations can begin.
Introduction
Section titled “Introduction”xLLM implements multi-stream parallelism at the model layer, where the input batch is split into 2 micro-batches. One stream handles computation for the first micro-batch, another concurrently executes communication for the second micro-batch.
This overlap of computation and communication effectively hides the communication latency.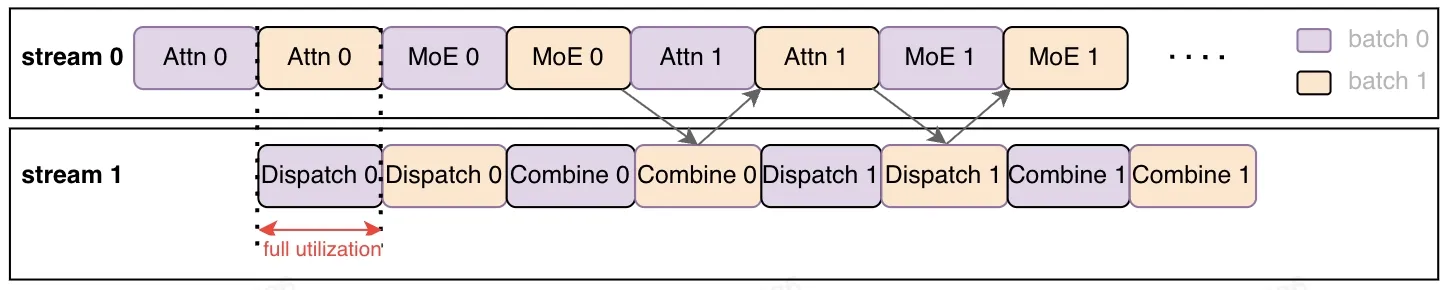
xLLM provides the gflags parameter enable_multi_stream_parallel, which defaults to false. To enable this feature, set it to true in xLLM’s service startup script, as:
--enable_multi_stream_parallel=truePerformance
Section titled “Performance”With prefill dual-stream parallelism enabled, it can effectively mask over 75% of communication overhead. On the DeepSeek-R1 model, when generating just 1 token, this achieves:
- 7% reduction in TTFT.
- 7% throughput improvement.
Notice
Section titled “Notice”The dual-stream parallelism currently only supports the prefill phase, with greater performance benefits observed for longer input requests. Only Support DeepSeek, Qwen3 dense(non-MoE) models.