Async schedule
Background
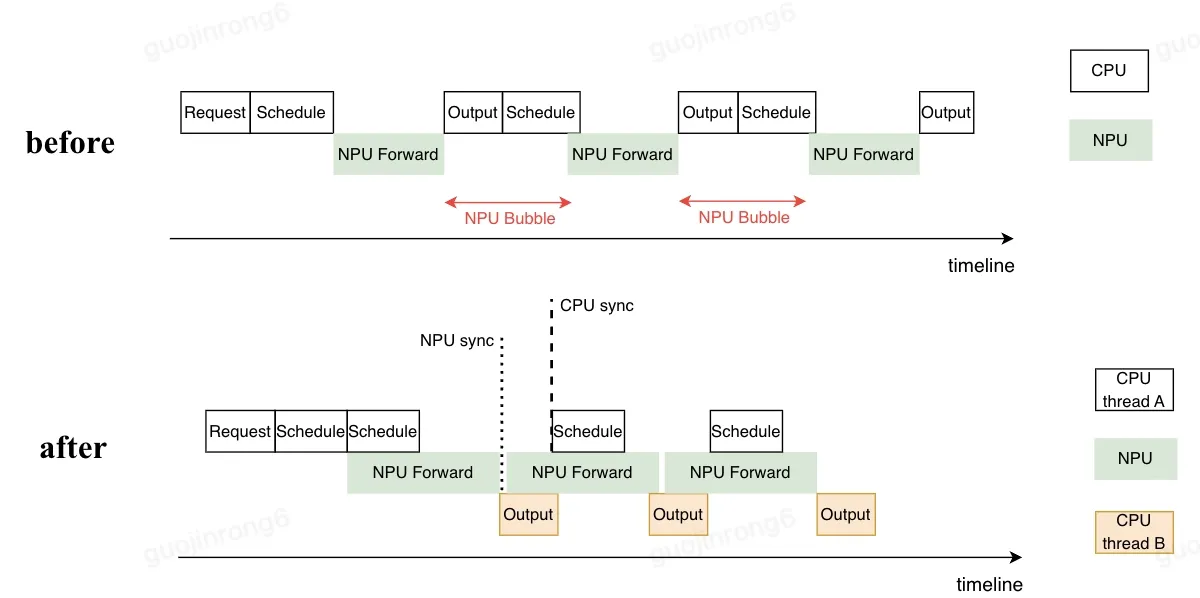
Section titled “Background”The inference process of large language models can be divided into three sequential stages:1) CPU-side scheduling (preparing model inputs), 2) Device computation (GPU/TPU execution), 3) CPU-side post-processing (output handling). Due to the sequential nature of decoding operations, the input for step-i+1 depends on the output of step-i. This forces strict serial execution of all three stages, creating device idle periods (“bubbles”) during CPU-bound stages 1 and 3, leading to suboptimal resource utilization.
Introduction
Section titled “Introduction”xLLM addresses this at the framework level by supporting asynchronous scheduling, where the CPU proactively executes scheduling operations for step-i+1 while the device is computing step-i. This allows the device to immediately begin computing step-i+1 upon completing step-i, thereby eliminating bubbles. Specifically, after initiating the computation call for step-i, the CPU does not wait for the device to finish computing. Instead, it constructs fake tokens for the step-i request, uses these fake tokens to perform scheduling operations for step-i+1 (such as allocating KV Cache), and replaces them with the true tokens computed in step-i when launching step-i+1 computation to ensure correctness. Meanwhile, the CPU processes the results of step-i in a separate thread and returns them to the client.
In the overall architecture, stages 1 and 3 on the CPU side are handled by different thread pools, and RPC function calls employ non-blocking C++ future and promise mechanisms to achieve a fully asynchronous runtime.
xLLM provides the gflags parameter enable_schedule_overlap, which defaults to false. To enable this feature, set it to true in xLLM’s service startup script:
--enable_schedule_overlap=truePerformance
Section titled “Performance”- With asynchronous scheduling enabled, the device idle time between two steps is approximately 200us - comparable to a single kernel launch duration.
- On the DeepSeek-R1-Distill-Qwen-1.5B model with TPOT constrained to 50ms, this achieves 17% throughput improvement.
Notice
Section titled “Notice”The asynchronous scheduling feature requires the server to compute one additional step. For use cases involving limited output tokens (e.g., few-token generation) or single-output scenarios like embedding models, enabling this feature is not recommended as it may reduce server-side throughput, thus hard-disabled internally. The VLM model is currently being adapted, will be temporarily disabled.