Generative Recommendation Design Document
Overview
Section titled “Overview”xLLM provides generative recommendation inference through the backend=rec path. The goal is not to replace the existing recommendation system, but to reuse the LLM inference engine in the recommendation pipeline while keeping the original predictor-side sparse feature processing and online serving capabilities. In practice, the LLM body is executed by xLLM, while the traditional recommendation system continues to handle feature preparation and online integration.
This document focuses on the following topics:
- the goal and constraints of generative recommendation inference
- model structure and integration architecture
- why the REC path prefers fixed scheduling and whole-graph multi-step execution
- how
xAttentionandbeam searchcooperate around memory efficiency and execution efficiency - where the core REC-related code is located in the current branch
The design goals of this document are:
- explain the
backend=recpath with a unified view - clarify the relation among fixed scheduling, multi-step execution, and custom kernels
- provide a stable base document for future technical sharing and code walkthroughs
The non-goals of this document are:
- full training details of recommendation models
- all online serving differences across business scenarios
- replacing detailed module-level API documents
1. Background and Problem
Section titled “1. Background and Problem”In recent years, LLM-based generative recommendation has made substantial progress. xLLM has also introduced support for recommendation inference. The goal of generative recommendation is not simply to attach an LLM to a recommendation system, but to use generative modeling to improve candidate expansion and ranking quality, especially metrics such as CTR.
In the current solution, xLLM serves as the unified inference engine and is integrated into the existing prediction pipeline through a shared library (.so) interface:
- the
predictorside continues to handle sparse feature processing, sample construction, and online service integration; - the
xLLMside is responsible for the LLM-related inference computation.
This split allows the original recommendation engineering capabilities to remain intact, while reusing xLLM’s infrastructure in operators, KV cache management, multi-backend execution, and scheduling.
However, generative recommendation and general LLM inference optimize for different targets.
- General LLM inference cares more about token-by-token interaction quality, such as returning the first result quickly, reducing the interval between generated tokens, and allowing requests to be inserted or ended dynamically.
- Generative recommendation cares more about total request latency and obtaining better candidate results within a limited number of decoding rounds.
The reason is straightforward: recommendation is usually not about generating an open-ended passage, but about expanding candidates, comparing candidates, and outputting the best result within a fixed number of rounds.
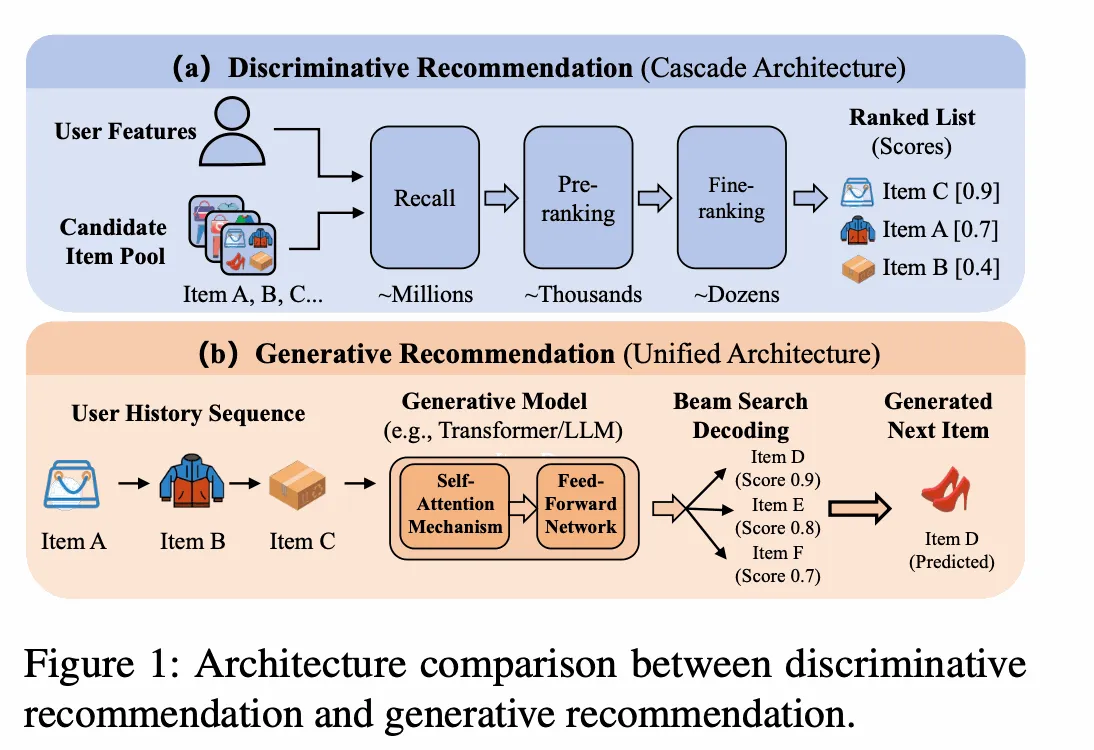
This path often uses beam search. In this context, beam search means that at each decoding round the system keeps multiple high-scoring candidate branches instead of only the best one, then keeps expanding and comparing them in later rounds. In recommendation, the purpose is not to generate longer text, but to cover more high-quality candidates within a small number of decoding rounds and improve the final recommendation quality.
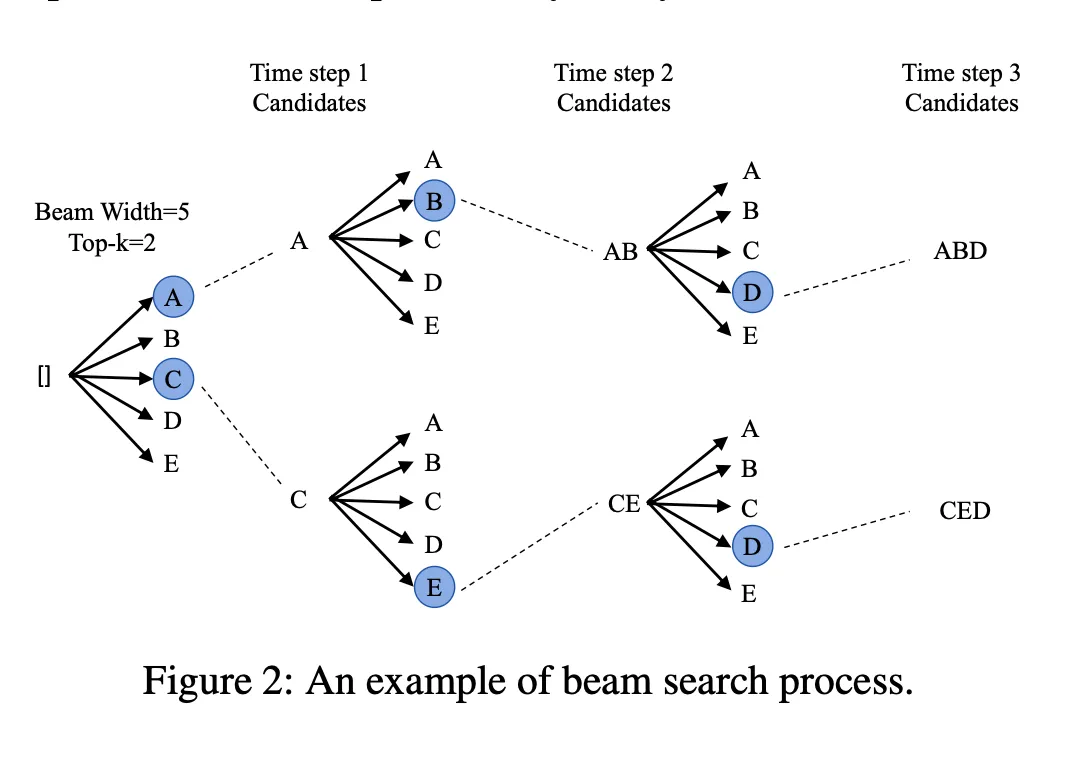
Therefore, generative recommendation naturally has two characteristics:
- fixed-step decoding;
- synchronized comparison of multiple candidates.
In other words, the real optimization target is not “make one sequence finish earlier”, but “push multiple candidates forward stably in a small number of rounds and compare them efficiently at each round”. This leads directly to the later design choice: fixed scheduling at the control layer and whole-graph multi-step execution at the execution layer, followed by custom operator optimization on top of that stable execution shape.
1.1 Workload characteristics: why GR is not just “another attention model”
Section titled “1.1 Workload characteristics: why GR is not just “another attention model””At a high level, generative recommendation still uses attention-based architectures, so it is easy to assume that its serving path can simply reuse the general LLM serving mindset. But the workload profile is very different.
Generative recommendation typically has the following characteristics:
- the prompt is long because it carries user history, context, and recommendation-side signals;
- the output is short because the system only needs a fixed-length item token sequence;
- the number of decode rounds is fixed and usually small;
- each decode round is still expensive because candidate expansion is often combined with a large
beam_widthandtop_k.
This forms a sharp contrast with general LLM inference:
- general LLM inference is usually “short prompt + long output”;
- generative recommendation is much closer to “long prompt + short output”.
So recommendation does not become cheap simply because the output is short. The decode phase is still expensive, and in many cases the expensive part is no longer only attention itself, but the system cost around candidate expansion and beam comparison.
1.2 Three core challenges of this workload
Section titled “1.2 Three core challenges of this workload”From the workload characteristics of generative recommendation itself, three challenge categories stand out clearly when compared with the general LLM inference path.
Challenge 1: long-prompt / short-output does not mean decode is cheap
Section titled “Challenge 1: long-prompt / short-output does not mean decode is cheap”Even though the decode length is fixed and small, each decode round may still be expensive. Shared-prefix reuse, repeated KV access across beams, and beam-related block movement all become more visible because the system is not amortizing them over a long free-form generation.
Challenge 2: beam search is not only an algorithmic issue
Section titled “Challenge 2: beam search is not only an algorithmic issue”In generative recommendation, beam search is not just a decoding technique for “better text quality”. It is part of the recommendation search process itself. Once beam_width and top_k increase, sorting, filtering, valid-item checking, candidate retention, and data-structure reuse all become system-level concerns.
Challenge 3: the bottleneck is also in host-device cooperation
Section titled “Challenge 3: the bottleneck is also in host-device cooperation”The system usually runs under strict online latency constraints and high concurrency. If the host still comes back at every step to decide whether to continue, prepare the next input, and resend control to the device, the host-side control path itself becomes a major part of the latency budget.
1.3 The role of this design document
Section titled “1.3 The role of this design document”This document does not try to reproduce an external paper or replace an experiment section. Its role is more practical: it brings the workload characteristics, the system-level problems, and the concrete implementation paths of the current branch into one place, so that later talks, reviews, and code walkthroughs can all use the same technical base.
2. Inference Architecture
Section titled “2. Inference Architecture”2.1 Model Structure
Section titled “2.1 Model Structure”Generative recommendation has become one of the most important paradigm shifts in modern recommendation systems. It breaks the traditional recall-ranking-rerank cascade and pushes the task from discriminative matching toward generative prediction. This document focuses on two model families that have shown strong quality and have been deployed at scale: OneRec for recall and OneTrans for ranking.
A shared pattern across these models is that they keep the traditional recommendation signals such as user sequence features, user static features, and context features, then use an input adaptation layer to map heterogeneous recommendation inputs (discrete IDs, continuous values, sequences, and multimodal content) into embeddings that can be consumed by the LLM decoder. The model body itself is still an Encoder+Decoder or Decoder-only LLM structure, which means different parts of the model should be handled by different inference engines.
2.2 Inference Integration Architecture
Section titled “2.2 Inference Integration Architecture”Based on the model structure, the current solution splits the model into two groups:
- the input adaptation layer still belongs to the traditional CTR-style inference domain and is handled by the
predictorside; - the LLM body is handled by xLLM.
As the core LLM inference engine, xLLM provides two integration modes for generative recommendation: RPC integration and shared library (.so) integration.
2.2.1 RPC Integration
Section titled “2.2.1 RPC Integration”The current marketing and online recall scenarios mainly use the RPC-based integration mode. Its advantage is a clean service boundary, while the downside is the extra RPC overhead.
2.2.2 Shared Library Integration
Section titled “2.2.2 Shared Library Integration”Another mode is to embed xLLM into the predictor side as an internal inference engine for the LLM subgraph. This avoids RPC round trips and is more suitable for future low-latency scenarios.

3. Fixed Scheduling and Graph-style Execution
Section titled “3. Fixed Scheduling and Graph-style Execution”3.1 Fixed-Step Scheduling
Section titled “3.1 Fixed-Step Scheduling”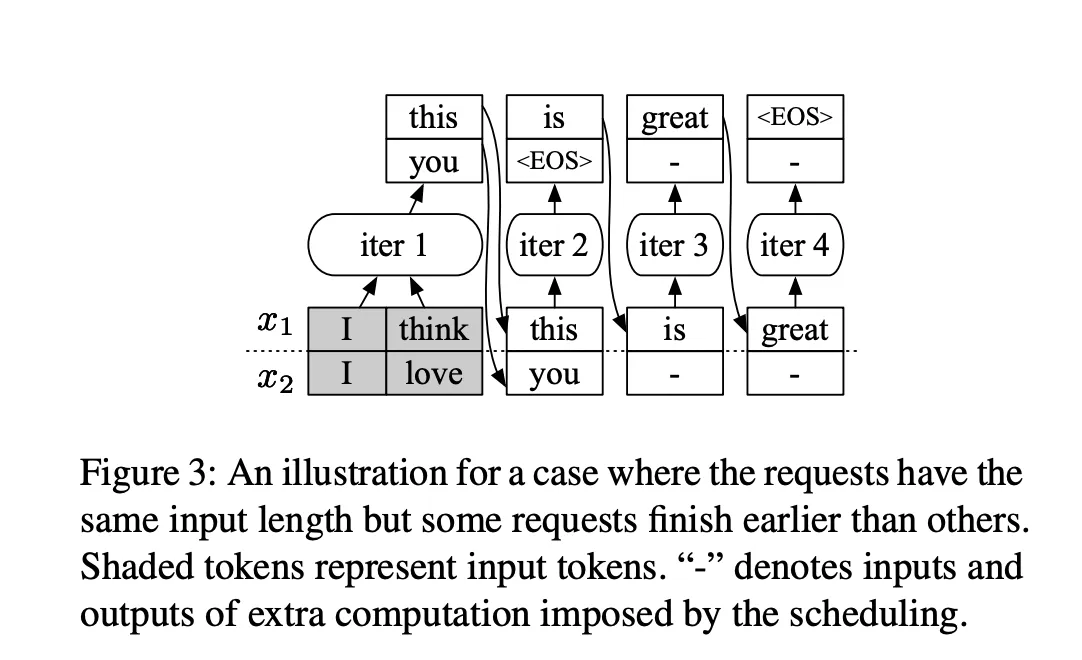
The figure above comes from the paper Orca: A Distributed Serving System for Transformer-Based Generative Models. It explains why continuous batching is useful for general text generation: it avoids idle compute caused by rigid fixed-batch execution.
Generative recommendation changes that assumption because the decoding length is fixed and the candidate set needs to move forward synchronously. As a result, the REC path is more suitable for fixed_steps_scheduler than for continuous batching. The reason is not simply “fixed rounds imply fixed scheduling”. The deeper reason is that the workload itself is organized as a fixed number of rounds. When requests usually finish in a predefined number of rounds and multiple candidate branches must move forward together, the scheduler should focus on sending one stable candidate group efficiently instead of inserting and removing requests at every step.
The first benefit of fixed_steps_scheduler is that it matches beam search better. In the decode stage, beam width is often large and multiple beams need to move and be compared in the same round. If continuous scheduling is used, every step may trigger batch rebuilding, sequence compaction, index remapping, and state pruning. Those operations make sense for general LLM inference because requests really do end dynamically. In generative recommendation, however, they are often additional cost instead of real value. Under fixed scheduling, the beam group of one request can move forward together inside one fixed window, without repeated batch rebuilding and repeated pruning decisions.
The second benefit is execution stability. Once the number of rounds, the beam-group size, and the advancing rhythm all become stable, many later optimizations become possible. Buffers can be allocated early, workspace can be reused more easily, and cache access patterns become more regular. This stability makes profiling and capacity planning easier and allows the execution path to be made much more stable.
The third benefit is that it reduces overhead outside the real model computation. In recommendation inference, the major cost should belong to candidate expansion, attention computation, and beam comparison. But if the scheduler keeps participating in sequence reordering, batch rebuilding, metadata refresh, and index movement at every step, then extra overhead is introduced even though it is not part of the actual operator work. In this sense, fixed scheduling trades stronger execution determinism for higher throughput, lower scheduling overhead, and more stable runtime behavior.
Of course, fixed scheduling also has a clear cost: a new request may wait longer. Under continuous scheduling, a new request may have a chance to be inserted after only one step. Under fixed scheduling, it often has to wait until the current fixed window finishes. This leads to a more visible queueing delay. The mitigation direction is not to go back to continuous scheduling, but to introduce multi-stream execution. The idea is to decouple the large request groups already running inside a fixed window from newly arriving small request groups and place them on different streams or execution channels. The purpose is not to eliminate waiting entirely, but to keep the throughput advantage of fixed scheduling while reducing the extra access latency of new requests.
3.2 Graph-style Multi-Step Execution
Section titled “3.2 Graph-style Multi-Step Execution”On top of fixed scheduling, multi_step_pipeline becomes the natural execution-side companion. It solves an execution-efficiency problem. Once we know the workload itself always runs a fixed number of rounds and does not usually end early, then there is no need to involve the host at every step. There is no need to perform a D2H synchronization every round just to ask whether the batch is finished, and there is no need to perform another H2D transfer every round just to prepare the next round’s input. A more efficient design is to prepare the space, indices, and data structures needed by later rounds at the first step, and then let the device continue advancing through the later rounds.
This brings several direct benefits:
- fewer
D2H/H2Dround trips and less host participation; - lower launch and control overhead at every round;
- better device-side data reuse because more intermediate data stays on device;
- a more pipeline-like execution flow instead of a repeated stop-prepare-run cycle.
For a fixed-round recommendation workload, this is clearly more efficient than returning to the host after every step.
Another important but often underestimated benefit of multi_step_pipeline is that it creates a better execution environment for custom operators. This is the point where xAttention and beam search custom kernels can be discussed together. fixed step solves scheduling stability, while whole-graph multi-step execution plus custom kernels solves execution efficiency.
4. Memory Management and Operator Co-optimization
Section titled “4. Memory Management and Operator Co-optimization”4.1 Compute and Memory Bottlenecks
Section titled “4.1 Compute and Memory Bottlenecks”4.1.1 Model Input and Output Characteristics
Section titled “4.1.1 Model Input and Output Characteristics”In the current generative recommendation setup, an item ID is represented by a fixed-length token sequence. As a result, decode_step is a known small constant, for example 3. One request can be summarized as:
- one prefill stage with a long user-history context;
decode_steprounds of decode, where each round generates one token and the final token sequence is combined into an item ID.
Even if the number of decode rounds is small, the per-step cost is not small. To improve recall and diversity, generative recommendation often uses a large beam_width. In addition, each beam may expand to top_k candidates, and the system then selects the new beam set from a global candidate pool of beam_width × top_k. For example, when beam_width=512 and top_k=512, the candidate pool size of one decode round reaches 262144 (about 2.6×10^5). So although the number of rounds is limited, the search and KV access cost per step is still considerable.
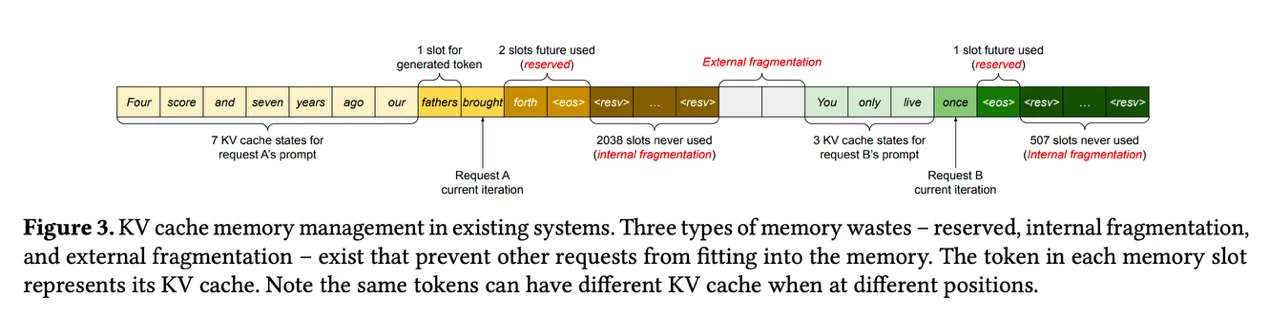
4.1.2 Storage Redundancy and Memory Fragmentation
Section titled “4.1.2 Storage Redundancy and Memory Fragmentation”The main bottlenecks of this inference service can be summarized into two groups, and xAttention is designed around both of them.
The first is redundant bandwidth consumption in attention. Shared prefixes are not explicitly represented as reusable structures. When beam width is large, all beams share the same long prompt, but a generic implementation often organizes KV as if every beam were a full independent sequence. This causes shared KV to be loaded repeatedly along the beam dimension and reduces the effective arithmetic intensity of the attention kernel, eventually making the path bandwidth-bound.
The second is KV cache copying and fragmentation. Beam search frequently forks and retires branches, which leads to beam reordering. For a block-based KV management scheme such as PagedAttention, “reordering + block alignment” often implies block copying, fragmentation, and extra memory waste. Both memory capacity and memory bandwidth get amplified in the wrong direction.
4.2 xAttention Design Principle
Section titled “4.2 xAttention Design Principle”4.2.1 KV Cache Layout Optimization
Section titled “4.2.1 KV Cache Layout Optimization”
Given the fixed structure of generative recommendation inference, xAttention redesigns both KV cache organization and the attention execution strategy. The shared prefix is stored only once at the physical-memory level, while beam branching and reordering no longer cause high-cost copying.
The first key idea is to split KV cache into two groups:
- Shared KV: prompt KV generated in prefill and shared by all beams;
- Unshared KV: newly generated KV in decode, managed at token granularity for each beam.
Once the cache is split this way, Unshared KV only stores the decode-generated tokens, which avoids both block copying and unnecessary memory waste.
4.2.2 Attention Compute Optimization
Section titled “4.2.2 Attention Compute Optimization”
To avoid concatenating Shared KV and Unshared KV into one long logical sequence, xAttention splits one attention computation into three stages:
- shared stage: compute local softmax statistics and partial outputs only on Shared KV;
- unshared stage: compute local statistics and partial outputs only on Unshared KV;
- merge stage: use OnlineSoftmax to merge the two parts stably.
At the parallelization level, shared, unshared, and merge are assigned to different execution units or queues to form a pipeline. The goal is to overlap Shared and Unshared computation as much as possible while minimizing synchronization points.
4.3 Treating beam search as a system problem
Section titled “4.3 Treating beam search as a system problem”If xAttention addresses the question “how can attention reuse shared context and avoid wasteful KV movement”, then this section addresses a different but equally important question: “how can beam search avoid turning recommendation decode into a sorting-heavy control bottleneck”.
From a systems perspective, beam search in recommendation carries several cost layers at once:
- each round must select a new beam set from a large candidate pool;
- not every token combination corresponds to a valid item;
- old candidates are discarded while new candidates are constantly introduced;
- if the implementation rebuilds data structures and performs full sorting every round, the overhead grows quickly.
So this part should be understood less as “one sorting kernel” and more as a system-level optimization strategy around beam search. Its goals include:
- terminate unnecessary sorting work as early as possible;
- filter invalid item paths as early as possible;
- reuse data structures across rounds instead of reconstructing them repeatedly.
For a technical talk, the key message here is that beam search is not an accessory cost in recommendation serving. It is part of the main decode cost, and therefore has to be designed together with scheduling, memory layout, and hot operator paths.
4.4 A system-level view of overlap and parallelism
Section titled “4.4 A system-level view of overlap and parallelism”The third challenge is not that one operator is slow, but that the whole serving pipeline is not naturally shaped for the recommendation workload. In this document, this refers to the system-level effort to maximize overlap across host-side scheduling, engine-side execution, worker-side multi-round progression, and stream-level parallelism.
At least three ideas belong to this layer:
-
clearer host-device role split
- the host should participate less in every round;
- the device should carry more of the fixed-round progression directly.
-
more pipeline-friendly execution
- while the current round is being executed, next-round inputs should already be under preparation;
- scheduler, batch builder, and worker should avoid introducing unnecessary idle boundaries.
-
multi-stream and multi-pipeline concurrency
- a fixed execution window naturally increases waiting cost for new requests;
- but that cost can be partially offset through multiple streams or multiple execution pipelines.
So, in the context of this document, this section is best understood as the system layer that combines fixed-step stability, device-side multi-step progression, and multi-stream overlap into one serving strategy.
4.5 Why this design direction is worth the effort
Section titled “4.5 Why this design direction is worth the effort”From the workload characteristics of generative recommendation, treating it as a special serving path is not over-engineering. It has clear system-level value.
The reason is that this workload combines several properties that do not usually appear together in the general LLM path:
- the input is long while the output is short;
- the decode rounds are fixed, but one decode round is still expensive;
- both
beam_widthand candidate-pool size are non-trivial; - host-side control, batch rebuilding, and data movement can easily dominate the latency budget.
As a result, simply reusing the general path tends to preserve unnecessary system cost. Once fixed-step scheduling, multi-step execution, shared/unshared KV design, beam search handling, and multi-stream overlap are considered together, the gain can appear at multiple levels at once: lower scheduling cost, less host participation, a cleaner memory layout, and a more stable hot path for custom operators.
This also gives the technical talk a strong closing point for this section: the reason to separate recommendation from the general LLM path is not just conceptual neatness, but the fact that recommendation decode really creates a different serving problem, and the payoff of handling it explicitly can be significant.
5. Code Layout
Section titled “5. Code Layout”The current branch organizes the generative recommendation path as follows.
External integration:
xllm/c_api/rec.hxllm/c_api/internal/rec.cppxllm/c_api/examples/simple_rec_completions.cpp
Service entry:
xllm/api_service/rec_completion_service_impl.cppxllm/api_service/chat_service_impl.cppxllm/api_service/api_service.cppxllm/api_service/api_service.h
Scheduling and engine:
xllm/core/distributed_runtime/rec_master.cppxllm/core/distributed_runtime/rec_master.hxllm/core/scheduler/fixed_steps_scheduler.cppxllm/core/scheduler/fixed_steps_scheduler.hxllm/core/distributed_runtime/rec_engine.cppxllm/core/distributed_runtime/rec_engine.h
Batch / request / proto:
xllm/core/framework/batch/rec_batch_input_builder.cppxllm/core/framework/batch/rec_batch_input_builder.hxllm/core/framework/batch/rec_multi_round_batch_input_builder.cppxllm/core/framework/batch/rec_multi_round_batch_input_builder.hxllm/core/framework/request/rec_type.hxllm/proto/rec.protoxllm/proto/completion.protoxllm/proto/xllm_service.proto
Runtime / worker:
xllm/core/runtime/rec_worker_impl.cppxllm/core/runtime/rec_worker_impl.h
Kernel hot path:
xllm/core/layers/cuda/xattention.cppxllm/core/layers/cuda/flashinfer_attention.cppxllm/core/kernels/cuda/xattention/beam_search.cppxllm/core/kernels/cuda/xattention/cache_select.cu
6. Current-branch Execution Flow
Section titled “6. Current-branch Execution Flow”To align the design with the actual implementation, the current branch can be understood as the following execution chain:
-
External entry
- In shared-library mode, requests enter from
xllm/c_api/internal/rec.cppthroughxllm_rec_text_completions,xllm_rec_token_completions, orxllm_rec_chat_completions. - In service mode, requests enter from
xllm/api_service/rec_completion_service_impl.cpporchat_service_impl.cpp, and are then forwarded toRecMaster.
- In shared-library mode, requests enter from
-
Request convergence in
RecMasterRecMasterunifies different request forms such as prompt input, token input, and raw embedding input.- It also distinguishes
kOneRecandkLlmRec, then selects the corresponding request pipeline.
-
Entering fixed scheduling
RecMastercreatesFixedStepsSchedulerdirectly during initialization.- Instead of rebuilding decode batches dynamically at every step, the scheduler is centered on a fixed number of rounds and a stable candidate group.
-
Engine execution
RecEnginethen selects an execution path according toRecPipelineType.- For the
LlmRecmulti-round scenario, execution is routed intoRecMultiRoundEnginePipeline, which pushes more decode control logic down toward the worker side.
-
Batch building and input construction
RecBatchInputBuilderandRecMultiRoundBatchInputBuilderorganize sequences, step information, decode positions, sampling parameters, and other metadata intoForwardInput.step_metais especially important here because it provides the per-round information needed for multi-step execution.
-
Multi-round execution inside the worker
RecWorkerImpl::LlmRecMultiRoundPipeline::step()performs a device-side round loop.- For each round, it coordinates:
- current-round input preparation
- model forward
- sample processing
- beam search
- cache selection
- preparation for the next round
-
Hot operator path
- Attention-related execution goes through
xattention.cppandflashinfer_attention.cpp - Beam-related selection goes through
beam_search.cpp - Cache selection after beam reordering goes through
cache_select.cu
- Attention-related execution goes through
From a technical-sharing perspective, this chain is a useful narrative backbone because it connects fixed scheduling, whole-graph multi-step execution, and custom kernels into one coherent execution story instead of presenting them as isolated optimizations.
7. Trade-offs and Applicability Boundaries
Section titled “7. Trade-offs and Applicability Boundaries”This design does not mean that fixed scheduling is always better than continuous scheduling, nor does it mean that multi-step pipeline execution fits every generation task. It works well because the current generative recommendation workload has a few specific characteristics:
- the number of decode rounds is relatively fixed and requests usually do not terminate early like open-ended text generation;
- one request often carries a large
beam_width, and multiple beams must be compared synchronously; - total request latency matters more than token-by-token interactivity;
- device-side state such as KV cache, positions, and beam tensors can be prepared and reused in a relatively stable way.
When those conditions hold, fixed scheduling and multi-step execution provide clear benefits. At the same time, they also have clear boundaries:
7.1 Boundary of fixed scheduling
Section titled “7.1 Boundary of fixed scheduling”- If request lengths vary dramatically and a large number of requests end early, continuous scheduling regains its advantage.
- If the business priority is to insert new requests as soon as possible, fixed scheduling naturally becomes less attractive.
- If candidate expansion no longer depends on synchronized beam progression, the benefit of a fixed execution window decreases.
7.2 Boundary of multi_step_pipeline
Section titled “7.2 Boundary of multi_step_pipeline”- If each step still requires strong host-side decisions, the value of device-side multi-step execution becomes smaller.
- If shape, batch layout, or key inputs change significantly at every round, it becomes much harder to keep a stable whole-graph execution path.
- If backend operators themselves are not ready for stable multi-round device-side execution, whole-graph execution will remain only a conceptual idea.
7.3 Boundary of custom operators
Section titled “7.3 Boundary of custom operators”xAttention and custom beam search kernels are valuable because the execution shape is already stable enough. Without fixed-step scheduling and multi-step device-side progression, many operator-level optimizations would be diluted by repeated data movement, batch rebuilding, and extra host participation.
So the more accurate order of reasoning is:
- first confirm that the workload truly fits fixed scheduling;
- then confirm that multi-round execution can be pushed down to the device side;
- only then optimize the stable hot path with custom operators.
This is what makes fixed_steps_scheduler, multi_step_pipeline, xAttention, and beam search a coherent design stack rather than four unrelated optimization tricks.
8. Code Path Appendix
Section titled “8. Code Path Appendix”The purpose of this appendix is not to repeat the file list in the previous section, but to provide a practical reading order. If someone later wants to expand this document, prepare a technical talk, or walk through the implementation, the following path is a more useful starting point.
8.1 Start from the external entry
Section titled “8.1 Start from the external entry”If the goal is to understand how predictor or the shared-library integration enters xLLM, start with:
xllm/c_api/rec.h- exposes
xllm_rec_create,xllm_rec_initialize,xllm_rec_text_completions,xllm_rec_token_completions, andxllm_rec_chat_completions - useful for understanding what the REC-facing external contract looks like
- exposes
xllm/c_api/internal/rec.cpp- the actual CAPI implementation
- useful for seeing how request parameters are wrapped and forwarded in
.somode
xllm/c_api/examples/simple_rec_completions.cpp- the smallest runnable example
- useful when explaining what a dynamic-library integration looks like in practice
If the technical-sharing version needs one “minimal usage example”, this is the best layer to cite first.
8.2 Then read the service entry layer
Section titled “8.2 Then read the service entry layer”If the focus is on RPC mode or the unified service path, continue with:
xllm/api_service/api_service.cpp- dispatches service implementations according to
FLAGS_backend - under
backend == "rec", bothrec_completion_service_impl_andchat_service_impl_are attached
- dispatches service implementations according to
xllm/api_service/rec_completion_service_impl.cpp- forwards REC completion requests into
RecMaster - this is where
routing,input_tensors, andRequestParamsare assembled together
- forwards REC completion requests into
xllm/api_service/chat_service_impl.cpp- also provides a chat entry for
RecMaster - useful to show that REC is not limited to token completion only
- also provides a chat entry for
This layer is useful in a technical talk when explaining that backend=rec is not a side path outside the service framework, but a first-class backend integrated into the existing service entry.
8.3 Then read scheduling and engine as one chain
Section titled “8.3 Then read scheduling and engine as one chain”If the main story is “why fixed step is a better fit for REC”, a practical reading order is:
xllm/core/distributed_runtime/rec_master.hxllm/core/distributed_runtime/rec_master.cppxllm/core/scheduler/fixed_steps_scheduler.hxllm/core/scheduler/fixed_steps_scheduler.cppxllm/core/distributed_runtime/rec_engine.hxllm/core/distributed_runtime/rec_engine.cpp
The chain can be understood as:
Rec request -> RecMaster -> FixedStepsScheduler -> RecEngine -> RecEnginePipeline -> Worker / worker_clientsThe most important takeaways in this layer are:
RecMasterconverges multiple request forms and chooses the request pipelineFixedStepsSchedulerorganizes requests into a batch shape that matches fixed-round progressionRecEnginebridges the scheduler output to the actual execution pathRecMultiRoundEnginePipelineis the concrete code path that represents “push multi-round decode control further down”
If the talk needs to prove that “fixed step is not just an idea but the actual code path”, this is the core evidence layer.
8.4 Read batch builders to understand why multi-step execution is possible
Section titled “8.4 Read batch builders to understand why multi-step execution is possible”To explain why multi_step_pipeline is possible, it is not enough to stop at the scheduler. The batch builder layer is equally important:
xllm/core/framework/batch/rec_batch_input_builder.hxllm/core/framework/batch/rec_batch_input_builder.cppxllm/core/framework/batch/rec_multi_round_batch_input_builder.hxllm/core/framework/batch/rec_multi_round_batch_input_builder.cppxllm/core/framework/batch/batch.cpp
The key points here are:
RecBatchInputBuilder::create(...)chooses different builders according toRecTypeand multi-round modeRecMultiRoundBatchInputBuilderis not just a small variation of the default builder, but a dedicated implementation for multi-round decode input constructionstep_meta,decode_positions,sampling params, andbatch forward typeare assembled here before being sent further into runtime
So if the document or talk wants to explain “why later rounds can already be prepared at the first step”, this layer is more important than only talking about the engine loop.
8.5 Read worker-side multi-round execution next
Section titled “8.5 Read worker-side multi-round execution next”The most valuable implementation details of multi_step_pipeline are inside:
xllm/core/runtime/rec_worker_impl.hxllm/core/runtime/rec_worker_impl.cpp
Especially these parts:
RecWorkerImpl::step_async(...)- shows how work is dispatched into the worker and onto the target stream
RecWorkerImpl::LlmRecMultiRoundPipeline::prepare_inputs(...)- shows how multi-round inputs enter runtime
RecWorkerImpl::LlmRecMultiRoundPipeline::allocate_kv_caches_related()- shows why fixed-step execution is friendly to early KV-related allocation
RecWorkerImpl::LlmRecMultiRoundPipeline::step(...)- this is the single most important function for multi-round execution
- it makes the relationship among round loop, beam search, cache select, and next-round preparation explicit
compute_next_round_input_async(...)- this is the key function when explaining why host round-trips can be reduced
If a technical talk wants to emphasize execution efficiency rather than scheduling policy, this is the best layer to expand.
8.6 Finally read the hot operator path
Section titled “8.6 Finally read the hot operator path”If the goal is to explain why xAttention and custom beam search kernels matter, the recommended reading order is:
xllm/core/layers/cuda/xattention.cppxllm/core/layers/cuda/flashinfer_attention.cppxllm/core/kernels/cuda/xattention/xattention_ops_api.hxllm/core/kernels/cuda/xattention/beam_search.cppxllm/core/kernels/cuda/xattention/cache_select.cu
This layer helps answer three questions:
- where the stable attention execution path actually lives
- why beam search is not only a scheduling topic but also a hot kernel path
- why cache selection after beam reordering must be discussed together with execution shape
In other words, if the technical-sharing narrative wants to connect fixed_steps_scheduler, multi_step_pipeline, xAttention, and beam search into one coherent story, it eventually has to land here.
8.7 Recommended reading order
Section titled “8.7 Recommended reading order”If this document is expanded further later, the recommended code-reading order is:
entry -> api_service -> RecMaster -> FixedStepsScheduler -> RecEngine -> RecBatchInputBuilder / RecMultiRoundBatchInputBuilder -> RecWorkerImpl::LlmRecMultiRoundPipeline -> xAttention / beam_search / cache_selectThe advantage of this order is that it matches how people usually understand the system:
- first, how the request enters the system
- then, why REC prefers fixed-step scheduling
- then, how multi-step execution is actually pushed down to the device side
- finally, why custom operators become valuable only after the execution shape becomes stable
This makes the logic easier to present in a technical talk and easier to reuse in future documentation work.
9. Key Code Anchor Index
Section titled “9. Key Code Anchor Index”If this design document is later extended into a technical talk, a PR explanation, or a deeper code walkthrough, the following anchors are the fastest way to connect the document back to the current branch implementation.
9.1 Entry and service-layer anchors
Section titled “9.1 Entry and service-layer anchors”xllm/core/distributed_runtime/rec_master.cpp:575RecMaster::handle_request(...)- prompt / prompt_tokens / input_tensors entry
xllm/core/distributed_runtime/rec_master.cpp:603RecMaster::handle_request(...)- chat-message entry
xllm/core/distributed_runtime/rec_master.cpp:651RecMaster::handle_request(const std::vector<int>& prompt_tokens, ...)- token / raw-input style entry
This group is useful when the talk needs to answer a simple question first: how exactly does a REC request get converged into RecMaster.
9.2 Scheduling anchors
Section titled “9.2 Scheduling anchors”xllm/core/scheduler/fixed_steps_scheduler.cpp:337FixedStepsScheduler::step(const absl::Duration& timeout)- the actual scheduling step that advances the fixed-step path
xllm/core/scheduler/fixed_steps_scheduler.cpp:186FixedStepsScheduler::prepare_batch()- useful for explaining how requests are grouped under fixed scheduling
xllm/core/framework/batch/rec_batch_input_builder.cpp:29RecBatchInputBuilder::create(...)- useful for explaining how builders are selected according to
RecTypeand multi-round mode
Taken together, these anchors are strong evidence that fixed-step scheduling is not just a conceptual preference but the actual scheduling choice in the code path.
9.3 Engine and multi-round execution anchors
Section titled “9.3 Engine and multi-round execution anchors”xllm/core/distributed_runtime/rec_engine.cpp:901RecEngine::RecMultiRoundEnginePipeline::step(...)- shows how engine-side execution is pushed into the multi-round pipeline
xllm/core/runtime/rec_worker_impl.cpp:849RecWorkerImpl::LlmRecMultiRoundPipeline::step(...)- the single most important multi-round execution function on the worker side
xllm/core/runtime/rec_worker_impl.cpp:1011- call site of
xllm::kernel::cuda::beam_search(...)
- call site of
xllm/core/runtime/rec_worker_impl.cpp:1066- call site of
xllm::kernel::cuda::cache_select(...)
- call site of
If the talk needs to make it explicit that beam search and cache select are not only “scheduling concepts” but hot device-side execution paths, this is the right group of anchors to cite.
9.4 How to use this anchor list
Section titled “9.4 How to use this anchor list”This list does not need to be repeated in the main narrative, but it is especially useful as:
- a “code evidence” slide in a technical talk
- a “key implementation locations” section in a PR description
- a quick response set when a reviewer asks where a specific statement comes from
If the document is extended further later, these anchors are also the most practical starting points for adding deeper function-level explanations.
10. Suggested Talk Order and Reading Strategy
Section titled “10. Suggested Talk Order and Reading Strategy”The previous sections, especially the code-path appendix and the key-code anchor list, are useful as a reference base. But if this document is later turned into a real technical talk, it also needs a more presentation-friendly reading order.
10.1 Recommended talk order
Section titled “10.1 Recommended talk order”If the audience is not directly involved in implementing backend=rec, the talk should not start from RecWorkerImpl or beam_search.cpp. A more effective order is:
-
Start from the business goal
- explain why generative recommendation and general LLM inference optimize for different targets
- explain why recommendation cares more about end-to-end request latency and fixed-round candidate comparison
-
Then explain the scheduling choice
- why
fixed_steps_scheduleris a better fit for this workload - why a large
beam_widthmakes fixed scheduling more valuable than continuous scheduling
- why
-
Then explain the execution model
- why
multi_step_pipelinecan push multi-round decode control further down to the device side - why this reduces host round-trips and control overhead
- why
-
Then explain custom operators
- why
xAttentionandbeam searchoptimizations become meaningful only after the execution shape becomes stable - why those two topics should be presented together rather than as isolated tricks
- why
-
Finally return to the code
- use the code path and key anchors to prove the previous conclusions
This order works well because the audience first understands the design motivation, then the execution strategy, and only after that the implementation evidence.
10.2 For internal code walkthroughs, the order can be reversed
Section titled “10.2 For internal code walkthroughs, the order can be reversed”If the audience already works on xLLM or recommendation infrastructure, the order can be more implementation-driven:
- start from
RecMaster -> FixedStepsScheduler -> RecEngine - then
RecBatchInputBuilder - then
RecWorkerImpl::LlmRecMultiRoundPipeline - finally
xAttention / beam_search / cache_select
This path is more efficient for an internal walkthrough because it follows the actual call stack. The downside is that it pushes new readers into implementation detail before they have the design context.
10.3 The three takeaways worth remembering
Section titled “10.3 The three takeaways worth remembering”If the document is later compressed into a short technical presentation, the whole design can be summarized into three lines:
fixed_steps_schedulersolves scheduling stability;multi_step_pipelinesolves multi-round execution efficiency;xAttentionandbeam searchcustom kernels turn that stable execution shape into real performance gains.
Those three lines are the most important part to remember. The rest of the document can be seen as evidence supporting them.
11. Comparison with the General LLM Inference Path
Section titled “11. Comparison with the General LLM Inference Path”To avoid treating backend=rec as “just another small variation of LLM inference”, it is useful to compare it explicitly with the general LLM inference path.
11.1 Different optimization targets
Section titled “11.1 Different optimization targets”General LLM inference is usually optimized for token-by-token generation experience: return the first result quickly, keep the token interval small, and allow new requests to enter as early as possible.
backend=rec, in contrast, is optimized for candidate expansion and comparison within a fixed number of rounds, so the primary concern becomes end-to-end request latency rather than the earliest completion of one sequence.
That means both paths perform decode, but the target is already different:
- general LLM inference is more about dynamic request management
- generative recommendation is more about synchronized progression inside a fixed execution window
11.2 Different scheduling focus
Section titled “11.2 Different scheduling focus”In general LLM inference, continuous scheduling is valuable because:
- some sequences can end early and free space immediately
- batches can be rebuilt continuously
- dynamic insertion and dynamic exit are frequent and meaningful
In backend=rec, the picture is different:
- the number of decode rounds is more fixed
beam_widthis larger- multiple candidates under the same request must be compared in the same round
- frequent batch rebuilding tends to amplify scheduling cost rather than reduce it
So the key difference is not simply “fixed-step vs continuous”, but “stability-first scheduling” versus “flexibility-first scheduling”.
11.3 Different execution model
Section titled “11.3 Different execution model”General LLM inference often allows the host to continue participating at each decode step, including step completion checks and next-step preparation.
Generative recommendation, because of its fixed-round and synchronized-candidate nature, benefits more from preparing multi-round structures early and letting the device continue forward.
That is why multi_step_pipeline is especially valuable here: it is not only about removing a few memcpy calls, but about replacing a host-driven step-by-step control model with a device-side multi-round progression model.
11.4 Different way to realize operator-level gains
Section titled “11.4 Different way to realize operator-level gains”In general LLM inference, operator optimization often directly improves one decode step or the generic attention path.
In backend=rec, the gain of operator optimization depends much more on whether the execution shape has already been stabilized.
If fixed scheduling is not established and batches are still rebuilt frequently, or if multi-step execution is not established and the host still repeatedly intervenes, a large part of the operator-level gain will be diluted by extra data movement and control overhead.
That is why the more accurate order in recommendation is:
- stabilize scheduling first
- push multi-round execution to the device side
- optimize the stable hot path with
xAttention,beam search, andcache_select
11.5 Design boundaries and applicability conditions
Section titled “11.5 Design boundaries and applicability conditions”The purpose of this comparison is not to claim that generative recommendation and general LLM inference are completely unrelated. The real purpose is to make it explicit which parts can be reused from the general path and which parts must be redesigned around the backend=rec workload.
From the analysis above, fixed_steps_scheduler, multi_step_pipeline, xAttention, and beam search need to be discussed together because they depend on the same preconditions:
- output length is fixed or approximately fixed;
- the number of decode rounds is small, but the cost of one round is still high;
- one request maintains a relatively large
beam_width; - candidate expansion and candidate comparison are part of the main serving path rather than optional post-processing;
- device-side state can be prepared early and reused across later rounds.
Only when these conditions hold at the same time do fixed scheduling and whole-graph multi-step execution deliver stable gains. Once these conditions disappear, for example because requests vary dramatically in length, many sequences terminate early, or new-request latency matters more than throughput, the current backend=rec design may no longer be the best choice.
It is also important to note that these four parts are not parallel ideas. They form a layered dependency:
The first layer is fixed_steps_scheduler. It stabilizes the scheduling entrance. If the scheduler still rebuilds batches and prunes sequences at every step, the later execution path cannot become stable.
The second layer is multi_step_pipeline. It stabilizes the progression of multi-round execution. Only after the scheduling window is stable does it become meaningful to push input preparation, KV organization, and round progression further down to the device side.
The third layer is xAttention. It addresses the memory and bandwidth behavior of attention in the recommendation workload. It only pays off consistently when execution itself has already become stable enough.
The fourth layer is beam search optimization. It reduces search and filtering cost under a large candidate space, but because beam logic directly participates in the main decode path, it cannot be treated as an isolated post-processing step.
In short, the current branch should be understood not as four independent optimizations, but as one layered design shaped by the recommendation workload itself.
11.6 Scenarios where the benefit is limited
Section titled “11.6 Scenarios where the benefit is limited”To avoid treating the current design as a universal answer, its boundaries should also be stated explicitly.
The first category is where fixed scheduling is not ideal. If request lengths vary dramatically, many sequences terminate early, or the system cares more about the earliest insertion of a new request than about total batch throughput, continuous scheduling may become more attractive again.
The second category is where whole-graph multi-step execution is hard to sustain. If each round still requires strong host-side decisions, or if shape, batch layout, or key inputs change significantly from round to round, then the benefits of multi_step_pipeline become weaker.
The third category is where operator-level gains are limited. If beam size is small, candidate expansion is cheap, or the shared prefix is short, the engineering payoff of xAttention and beam-related optimization may still exist, but it will be much smaller than in a typical recommendation-serving workload.
Writing down these boundaries is useful for two reasons: it prevents readers from assuming unconditional applicability, and it gives reviewers a clearer way to distinguish between design assumptions and implementation defects.
12. Verification and Acceptance Guidance
Section titled “12. Verification and Acceptance Guidance”Verification should not stop at “the document renders correctly”. It should also answer whether the implementation in the current branch actually supports the design described in this document.
12.1 Document-level verification
Section titled “12.1 Document-level verification”The most basic verification still matters:
- both the Chinese and English design documents render correctly;
- all image references resolve to actual files under
docs/assets/; - the English document points to English diagrams instead of Chinese-labeled figures;
- the entry pages and related feature pages can navigate to this design document.
This level of verification ensures that the document itself is consumable.
12.2 Code-path consistency verification
Section titled “12.2 Code-path consistency verification”The second level is to verify that the key paths described in the document really exist in the current branch and that their roles match the implementation:
- whether
RecMastertruly converges requests and selects the proper pipeline; - whether
FixedStepsScheduleris actually the fixed scheduling entry forbackend=rec; - whether
RecEngineis really the engine-side execution organizer; - whether
RecWorkerImpl::LlmRecMultiRoundPipelineis really the device-side multi-round execution path; - whether the paths of
xAttention,beam_search, andcache_selectmatch the design description.
This level prevents the document from becoming a “target architecture note” that no longer matches the branch.
12.3 Verification items tied to design goals
Section titled “12.3 Verification items tied to design goals”If this document is used as a stable base for implementation discussion or technical sharing, the verification items should also map directly back to the design goals.
For fixed scheduling, useful checks include:
- whether decode still rebuilds batches frequently;
- whether beam-related sequences still trigger heavy pruning and movement every round;
- whether scheduler overhead is actually reduced in profiling.
For multi_step_pipeline, useful checks include:
- whether the host still decides termination at every round;
- whether next-round inputs can already be prepared while the current round is executing;
- whether
D2H/H2Dround trips are reduced relative to a host-driven round-by-round path.
For xAttention, useful checks include:
- whether shared KV is really stored once at the physical-storage level;
- whether unshared KV really carries only decode-generated tokens;
- whether repeated loading of the shared prefix is reduced.
For beam search, useful checks include:
- whether sorting and filtering still dominate the cost under large
beam_width; - whether beam-related data structures are reused across rounds;
- whether item filtering and candidate screening are already integrated with the main decode path.
12.4 Final acceptance criteria
Section titled “12.4 Final acceptance criteria”If this document is treated as the design baseline of the current branch, then at minimum it should satisfy the following:
- document level: bilingual readability, complete references, and reachable navigation;
- structure level: the relationship among scheduling, execution, and custom operators is clearly described;
- code level: key paths, key functions, and key files can be matched to the branch;
- design level: assumptions, boundaries, and trade-offs are stated clearly;
- sharing level: a reader can extract a talk outline directly from the document without rebuilding the logic from scratch.
Only when those conditions are met does the document become a stable base shared by design discussion, technical sharing, and code review.
13. FAQ / Common Misconceptions
Section titled “13. FAQ / Common Misconceptions”Q1: Does fixed-step scheduling always outperform continuous scheduling?
Section titled “Q1: Does fixed-step scheduling always outperform continuous scheduling?”No. Fixed-step scheduling is a strong fit for the current backend=rec workload because the decode rounds are more fixed, beam_width is larger, and candidate comparison is more synchronized. If these assumptions disappear, continuous scheduling may become more attractive again.
Q2: Is multi_step_pipeline only about reducing memcpy calls?
Section titled “Q2: Is multi_step_pipeline only about reducing memcpy calls?”No. Fewer D2H/H2D round trips are only the most visible benefit. The more important change is the control model itself: instead of letting the host drive every round, the system pushes as much multi-round progression as possible down to the device side.
Q3: Why are xAttention and beam search discussed in the same section?
Section titled “Q3: Why are xAttention and beam search discussed in the same section?”Because they depend on the same condition: execution shape must already be stable. If the scheduler still rebuilds batches frequently, or the host still intervenes heavily at each round, then a large part of the operator-level gain will be diluted by system overhead.
Q4: Is this design only about OneRec?
Section titled “Q4: Is this design only about OneRec?”No. The document uses recommendation serving as the main narrative and often uses OneRec as an example, but the more important point is the workload shape behind backend=rec, not a single model name.
Q5: Why does the document repeatedly emphasize “stabilize scheduling first, optimize operators later”?
Section titled “Q5: Why does the document repeatedly emphasize “stabilize scheduling first, optimize operators later”?”Because order matters in system design. If the scheduling entrance is still unstable, and the execution path still depends heavily on host-side intervention, then operator-level optimization will struggle to produce stable end-to-end gains.
14. Contract and Invariants
Section titled “14. Contract and Invariants”If this document is expected to serve as a base for implementation and review, explanation alone is not enough. A few key contracts and invariants should be made explicit.
14.1 External input shapes
Section titled “14.1 External input shapes”At a high level, the current backend=rec path accepts at least three kinds of inputs:
- prompt-based input
- used when recommendation requests enter through text-like prompts
- token / raw input
- used when token sequences, embeddings, or related raw structures are already prepared outside
- chat-style input
- used when recommendation requests enter through a conversation-like service path
The key point is not the number of input forms, but the fact that all of them must eventually converge into one unified request state and one scheduler / engine / worker execution chain.
14.2 Key data that directly affects multi-round execution
Section titled “14.2 Key data that directly affects multi-round execution”For backend=rec, the following data items form the most important contract surface:
beam_width- controls how many branches are kept after each round
top_k- controls how many next-token candidates are expanded per branch
decode_step/total_round- defines the fixed-round boundary of execution
decode_positions- defines how token positions are organized across rounds
- shared / unshared KV
- defines how KV cache is split and reused in decode
If these data items are not organized early enough and consistently enough, the gains of fixed-step scheduling and multi-step execution will not remain stable.
14.3 Invariants that the document should keep stable
Section titled “14.3 Invariants that the document should keep stable”If this document continues to grow later, the following invariants are worth preserving:
- whenever the document mentions fixed-step scheduling, it should also explain the boundary conditions;
- whenever it mentions
multi_step_pipeline, it should state which host-side work is reduced; - whenever it mentions
xAttention, it should explain its dependency on KV organization; - whenever it mentions
beam search, it should treat it as part of the main serving cost rather than only an algorithmic trick; - all code anchors must continue to match the current branch and must not silently drift toward future paths.
15. Implementation Status Matrix
Section titled “15. Implementation Status Matrix”To avoid mixing design intent and branch reality, it is useful to make the current alignment explicit. This is not meant to be an exhaustive implementation matrix, but rather a stable summary of what the current document already treats as grounded facts.
15.1 Capabilities that already have concrete implementation anchors
Section titled “15.1 Capabilities that already have concrete implementation anchors”- fixed scheduling
- the current branch contains
FixedStepsScheduler - it can be cited as a concrete scheduling fact rather than a conceptual placeholder
- the current branch contains
- multi-round execution path
- the current branch contains
RecMultiRoundEnginePipeline - the worker side contains
LlmRecMultiRoundPipeline
- the current branch contains
- beam search hot path
- the current branch already contains beam-search-related call paths and kernels
- cache select hot path
- the current branch already contains cache-select-related call paths and kernels
- xAttention / flashinfer path
- the current branch already contains the relevant implementation files and call chain
15.2 Parts that still remain design-level abstractions in this document
Section titled “15.2 Parts that still remain design-level abstractions in this document”- the relationship among fixed scheduling, multi-step execution, and custom operators
- this document explains it as a system design
- it is not represented by one single class or one single file
- the end-to-end gain of multi-stream overlap
- the current branch contains the concurrency and stream infrastructure
- but the gain discussion in the document still belongs to system-level interpretation, not one single implementation object
15.3 Why this section matters
Section titled “15.3 Why this section matters”The point of this section is to prevent readers from confusing “the document presents a coherent design” with “every part of the design is already fully materialized in the current branch”. It helps reviewers and readers distinguish between implementation-grounded facts and system-level abstraction.
16. Failure Modes and Observability
Section titled “16. Failure Modes and Observability”If the document only explains the normal path, it still feels closer to a talk draft than to a technical design note. An online system also needs a clear view of failure modes and observability.
16.1 Typical failure modes
Section titled “16.1 Typical failure modes”- waiting time grows too much
- the fixed-step window increases queueing time for new requests
- beam becomes too large
- sorting, filtering, and candidate management dominate the cost
- shared / unshared KV is not organized correctly
- this can lead to memory waste, repeated loading, or wrong cache selection
- host participation remains too high
- this directly weakens the benefit of multi-step execution
- operator-level gains do not materialize
- this usually means the execution shape is not stable enough yet
16.2 What should be observed first
Section titled “16.2 What should be observed first”Even without a full monitoring chapter, the document should at least clarify the key observation points:
- end-to-end request latency
- per-round decode latency
- scheduler overhead ratio
- host-device round trips or synchronization points
- beam-search / cache-select share in total latency
- memory peak and fragmentation tendency
16.3 Shortest debugging path
Section titled “16.3 Shortest debugging path”When behavior does not match the design expectation, the following order is often the shortest path:
- verify that the request actually matches the fixed-step workload assumptions;
- verify that the decode path really enters the multi-round worker pipeline;
- verify whether beam search and cache select dominate the cost;
- finally verify whether xAttention and KV organization actually reduce repeated loading and copying.
17. Benchmark and Acceptance Protocol
Section titled “17. Benchmark and Acceptance Protocol”To make this design document more useful as a review and acceptance baseline, it is helpful to include a lightweight benchmark and acceptance template.
17.1 Recommended workload coverage
Section titled “17.1 Recommended workload coverage”- long input / short output
- the most representative generative recommendation scenario
- different beam_width settings
- for example, one moderate-beam case and one large-beam case
- different top_k settings
- useful for observing how search and filtering cost scales
17.2 Recommended metric set
Section titled “17.2 Recommended metric set”- throughput
- P50 / P95 / P99 latency
- per-round decode cost
- scheduler overhead ratio
- host participation overhead
- peak memory usage
17.3 Acceptance focus
Section titled “17.3 Acceptance focus”- whether fixed-step scheduling really reduces scheduling disturbance
- whether multi-step execution really reduces host-side round control overhead
- whether
xAttentionreally improves shared-prefix reuse - whether beam-related optimization really reduces search and filtering cost
The value of this section is that it turns “the design sounds reasonable” into “the design can be evaluated with a stable acceptance template”.
18. Key Parameters and Suggested Ranges
Section titled “18. Key Parameters and Suggested Ranges”To keep this document from remaining purely conceptual, it is useful to end with a lightweight parameter-oriented section. The purpose is not to declare one universally correct configuration, but to summarize which parameters matter the most and why.
18.1 beam_width
Section titled “18.1 beam_width”beam_width controls how many candidate branches survive after each round. It is one of the most important cost drivers in generative recommendation decode.
- when
beam_widthis smaller:- search cost is lower
- candidate coverage is weaker
- lower latency is easier to achieve
- when
beam_widthis larger:- candidate coverage is stronger
- sorting, filtering, and cache-select cost all increase
- the gain of fixed-step and multi-step execution becomes more visible, but decode-side cost also grows quickly
So beam_width should be treated as a core trade-off parameter among recommendation quality, total latency, and system overhead.
18.2 top_k
Section titled “18.2 top_k”top_k controls how many candidates are expanded from each beam in one round.
In a large candidate space, increasing top_k directly amplifies:
- sorting work
- invalid-item filtering work
- intermediate candidate-state management cost
If top_k is too large and invalid-item filtering happens too late, then a large amount of computation is spent on candidates that will never survive into the next round.
18.3 Decode-round count
Section titled “18.3 Decode-round count”The more stable the decode-round count is, the easier it is for fixed-step scheduling and multi-step execution to keep producing stable gains.
If the number of rounds stays within a small and predictable range, then:
- device-side structures can be allocated earlier;
step_metaremains easier to stabilize;- whole-graph multi-step execution becomes easier to exploit.
If the round count itself becomes unstable, one of the core assumptions behind the current design becomes weaker.
18.4 Multi-stream concurrency
Section titled “18.4 Multi-stream concurrency”More streams do not automatically mean better performance. Too few streams may fail to hide waiting cost, while too many streams may introduce additional contention, scheduling overhead, and resource competition.
A more reasonable tuning order is usually:
- confirm that fixed-step scheduling is already stable;
- confirm that host-side waiting and queueing are actually significant;
- only then increase multi-stream or multi-pipeline concurrency.
18.5 Suggested parameter-tuning order
Section titled “18.5 Suggested parameter-tuning order”If this path is tuned further later, the following order is usually more effective:
- first confirm that the decode-round count is stable;
- then tune
beam_width; - then tune
top_k; - only after that tune multi-stream and system overlap.
The reason is simple: the first two primarily determine workload shape, while the latter ones optimize the system under that shape.
19. References
Section titled “19. References”This document is implementation-oriented, but some of the background problems, serving ideas, and memory/graph execution context naturally come from public references. If the document is extended later, the following materials are useful anchor points.
19.1 Scheduling and serving systems
Section titled “19.1 Scheduling and serving systems”- Orca: A Distributed Serving System for Transformer-Based Generative Models
- useful as the background reference for continuous batching
- useful as a comparison point when explaining why REC prefers fixed-step execution
19.2 Memory management and KV cache
Section titled “19.2 Memory management and KV cache”- Efficient Memory Management for Large Language Model Serving with PagedAttention
- useful as a background reference for block-based KV management
- useful when explaining why shared/unshared KV separation matters
19.3 Generative recommendation models
Section titled “19.3 Generative recommendation models”- OneRec
- useful when describing the structure of recall-oriented generative recommendation models
- OneTrans
- useful when describing the structure of ranking-oriented generative recommendation models
19.4 Graph execution and multi-step execution
Section titled “19.4 Graph execution and multi-step execution”- the existing
Graph Modedesign document in this repository- useful for graph capture / replay, parameterization, and Piecewise Graph
- the current generative recommendation design document
- useful for fixed-step scheduling, multi-round decode, beam search, and xAttention as one coherent serving stack
19.5 Suggested use
Section titled “19.5 Suggested use”If the document is extended further later:
- read Orca first when writing scheduling background;
- read PagedAttention first when writing KV / memory layout background;
- return to OneRec / OneTrans when writing model-structure background;
- return to this document and the code-anchor appendix when writing implementation mapping.
This keeps future expansion grounded and prevents the document from turning into a loose collection of disconnected explanations.