xLLM Service
Project Overview
Section titled “Project Overview”xLLM-service is a service-layer framework developed based on the xLLM inference engine, providing efficient, fault-tolerant, and flexible LLM inference services for clustered deployment.
xLLM-service targets to address key challenges in enterprise-level service scenarios:
-
How to ensure the SLA of online services and improve resource utilization of offline tasks in a hybrid online-offline deployment environment.
-
How to react to changing request loads in actual businesses, such as fluctuations in input/output lengths.
-
Resolving performance bottlenecks of multimodal model requests.
-
Ensuring high reliability of computing instances.
Background
Section titled “Background”LLM with parameter scales ranging from tens of billions to trillions are being rapidly deployed in core business scenarios such as intelligent customer service, real-time recommendation, and content generation. Efficient support for domestic computing hardware has become a core requirement for low-cost inference deployment. Existing inference engines struggle to effectively adapt to the architectural characteristics of dedicated accelerators like domestic chips. Performance issues such as low utilization of computing units, load imbalance and communication overhead bottlenecks under the MoE architecture, and difficulties in kv cache management have restricted the efficient inference of requests and the scalability of the system. The xLLM-service + xLLM inference engine improves the efficiency of the entire performance link and it provides crucial technical support for the large-scale implementation of LLM in real-world business scenarios.
Overall Architecture
Section titled “Overall Architecture”The overall architecture of xLLM-service is shown in the figure below:
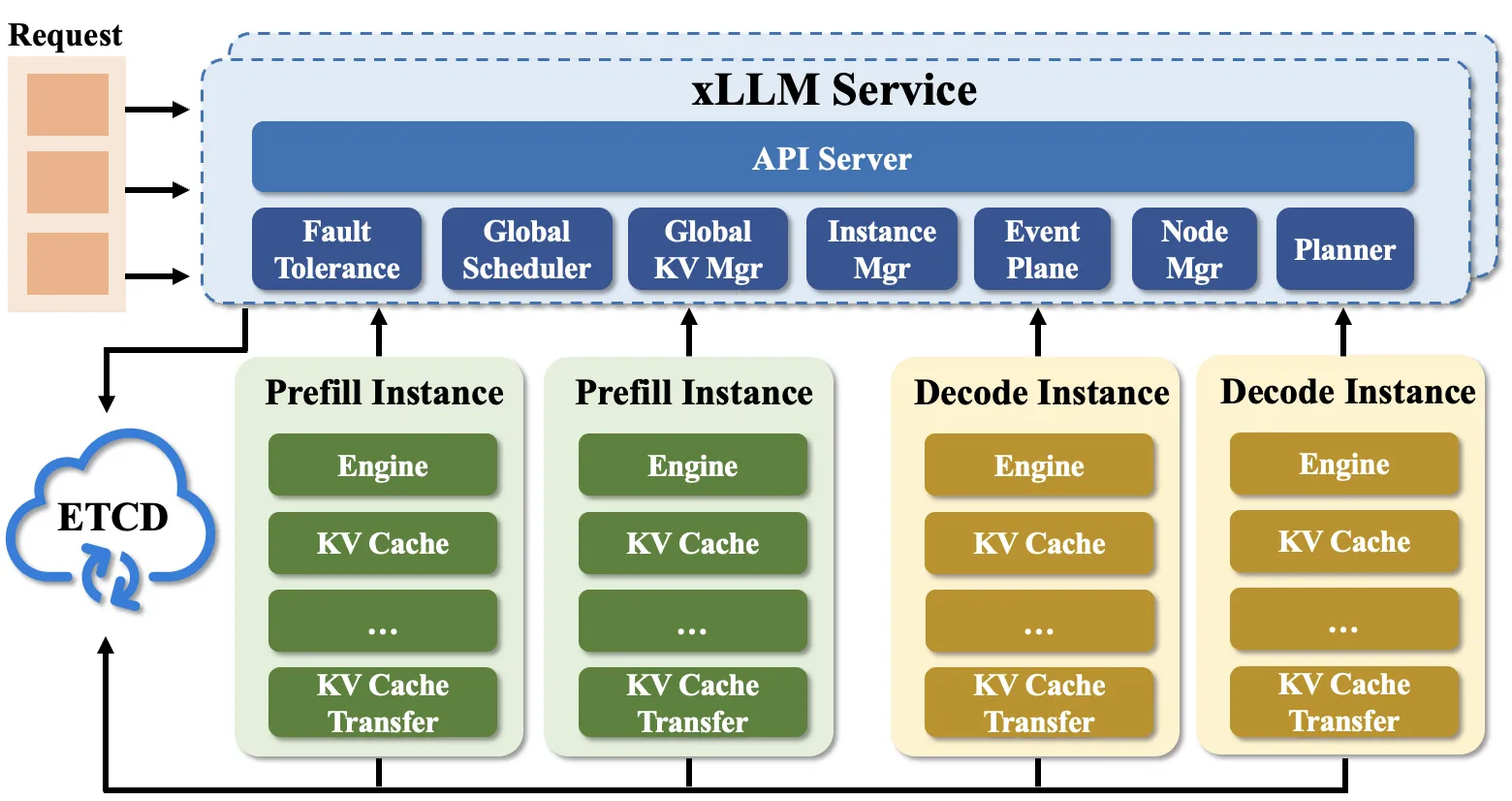
Core Components
Section titled “Core Components”ETCD Cluster
Section titled “ETCD Cluster”It is used for metadata management, including the storage and management of metadata such as models, xllm instances, and requests. It also provides xllm node registration and discovery services.
Fault Tolerance
Section titled “Fault Tolerance”xLLM-service provides fault tolerance management to ensure service quality and stability.
Global Scheduler
Section titled “Global Scheduler”It implements globally aware scheduling. Based on the current system status, it accurately dispatches requests to the optimal instances for execution, effectively improving the overall service response efficiency and resource utilization.
Global KV Cache Manager
Section titled “Global KV Cache Manager”It is responsible for global KV Cache management. Its core capabilities include distributed KV cache awareness, Prefix matching, and dynamic migration of KV Cache, which optimize the efficiency of cache resource usage.
Instance Manager
Section titled “Instance Manager”It focuses on the full-lifecycle management of instances. All xllm instances must register to service after startup. Based on preset policies, the module provides support for instances such as scheduling adaptation and fault tolerance handling.
Event Plane
Section titled “Event Plane”As the metrics and event hub, it receives Metrics data reported by various instances, uniformly collects and organizes statistical indicators, and provides data support for decisions such as service scheduling, fault tolerance, and scaling.
Planner
Section titled “Planner”It undertakes the functions of strategy analysis and decision-making. Based on the Metrics data reported by the Event Plane (including instance runtime indicators, machine load indicators, etc.), it analyzes the service scaling needs and the necessity of expanding hot instances, and outputs resource adjustment and instance optimization strategies.